
ISCC-Benchmark
von Patricia Schinke
In diesem Beitrag fassen wir kurz die Tests zusammen, die wir bisher während der Entwicklung des ISCC durchgeführt haben. Jede Komponente des ISCC soll gründlich getestet werden, um sicherzustellen, am Ende der Entwicklungsphase ein reibungslos funktionierendes Konzept zu erhalten.
Die erste Komponente des ISCC ist die Meta-ID. Sie wird von den Metadaten des Inhalts abgeleitet und soll dazu dienen, Inhalte leicht aufzufinden. Gleichzeitig soll sie helfen, verschiedene Versionen und Formate digitaler Inhalte zu gruppieren, und Datendeduplizierung vermeiden. Um unsere Konzepte hinsichtlich der Meta-ID des ISCCs zu testen, haben wir Metadaten und zugehörige ISBNs aus verschiedenen offenen Datenquellen gesammelt und unsere Tests an diesen Datensätzen vorgenommen. Die Ziele dieser Tests waren:
- Die Bestimmung der idealen Bitlänge für die Meta-ID
- Die Bestimmung der idealen Shingle-Size für das Hashing
- Die Suche nach weiteren Normalisierungs-Möglichkeiten für den ISCC
Die Tests mit Parsern für die unterschiedlichen Datenquellen sind auf Github zugänglich.
Unsere Datenquellen
| Bezugsquelle | Zahl der Einträge | Format | Url |
| Open Library | 25 Mio | JSON | openlibrary.org/developers/dumps |
| DNB | 14 Mio | RDF | datendienst.dnb.de/cgi-bin/mabit.pl |
| Harvard | 12 Mio | MARC21 | library.harvard.edu/open-metadata |
| BX Books | 271.379 | CSV | www2.informatik.uni-freiburg.de/~cziegler/BX/ |
Während des Parsens der Datenquellen werden nur jene Einträge hinzugefügt, die einen Titel, mindestens einen Autor und eine ISBN enthalten. Im Falle mehrerer Autoren werden alle Autoren getrennt durch „;“ hinzugefügt. ISBN-10 wird nach ISBN-13 konvertiert. Titel, Autor, ISBN und der Name der Datenquelle werden gespeichert; Einträge mit identischen Metadaten werden nur einmal gespeichert.
Unsere Tests
Während des Parsens haben wir alle geeigneten Metadaten in einem Elasticsearch-Index gespeichert. Anschließend haben wir die zugehörige Meta-ID für jeden Metadaten-Eintrag anhand des Titels und Autors erzeugt und ihn zusammen mit einem Link auf den Metadaten-Eintrag in einem weiteren Index gespeichert.
Um eine Vielzahl von Meta-IDs zu testen, kann der Meta-ID-Index zu einem späteren Zeitpunkt geleert werden, um dann wieder mit auf andere Art erzeugten Meta-IDs gefüllt zu werden. Auf diese Weise können wir unterschiedliche Meta-ID-Konfigurationen testen, ohne die Datenquellen für jeden Test neu parsen zu müssen.
Erster Testlauf
Beim ersten Testlauf wurden die Meta-IDs nach Meta-IDs gruppiert; bei diesem Prozess wurden nur jene Gruppen berücksichtigt, deren Einträge aus mindestens zwei unterschiedlichen Datenquellen stammten. Dann wurde gezählt, in wie vielen Gruppen jede Meta-ID mit derselben ISBN assoziiert ist, sowie wie viele Gruppen mindestens zwei Meta-IDs für Einträge mit unterschiedlichen ISBNs aufwiesen. Zwei Einträge mit identischer Meta-ID sollten dasselbe Werk referenzieren, also Werke mit der gleichen ISBN; wir haben demgemäß versucht, die erste Gruppe, die wir „echte Negative“ nennen, zu maximieren und die zweite Gruppe, die wir „falsche Negative“ nennen, zu minimieren.
Zweiter Testlauf
Im zweiten Testlauf wurden die Metadaten nach ISBN gruppiert; wie beim ersten Lauf wurden in diesem Prozess nur jene Gruppen berücksichtigt, deren Einträge aus mindestens zwei unterschiedlichen Datengruppen stammten. Dann wurden die Gruppen gezählt, deren jeweilige MetaID identisch war, sowie die Gruppen, die mindestens zwei verschiedene Meta-IDs hatten. Wie beim ersten Lauf wollten wir die erste Gruppe, die wir „echte Positive“ genannt haben, maximieren und die zweite Gruppe, die wir „falsche Positive“ nennen, minimieren, da zwei Einträge mit derselben ISBN für das gleiche Werk stehen und folglich die gleiche Meta-ID erhalten sollten.
Die Testergebnisse werden in einem weiteren Elasticsearch-Index gespeichert. Zusätzlich werden alle ISBNs und Meta-IDs mit Kollisionen in txt-Files gespeichert und sind so in der Elasticsearch nachverfolgbar. Es lassen sich jederzeit Diagramme für den Vergleich der unterschiedlichen Testergebnisse erzeugen.
Probleme
Während der Tests stießen wir auf verschiedene Probleme hinsichtlich der Resultate.
Langsames Parsing
Die Datenformate der Quellen sind vergleichsweise alt, und in einigen werden für die Autoren lediglich IDs angegeben. Wir mußten sie folglich abfragen und von einer separaten Datenquelle aus anbinden. Wir haben versucht, das Parsing so weit als möglich zu beschleunigen, zum Beispiel indem wir die Autoren und ihre IDs teilweise im Hauptspeicher gehalten haben. Um die Tests weiter zu beschleunigen, haben wir die Metadaten im Elasticsearch-Backend gespeichert. Auf diese Weise müssen die Daten nicht für jeden Testlauf neu geparst werden.
Werke können mehrere ISBNs haben
Häufig erhalten Werke für jede neue Auflage eine neue ISBN. Es gibt leider keine Buch-Kennung, die ein Werk über verschiedene Auflagen hinweg eindeutig referenziert. Dies ist eines der Probleme, das wir mit dem ISCC zu lösen versuchen, doch es ist schwer festzustellen, inwieweit die Meta-ID dieser Aufgabe gewachsen ist. Mangels Alternative haben wir dennoch die ISBN als Kennung verwendet und akzeptiert, dass die Ergebnisse negativer ausfallen.
Fehlerhafte Kodierung
In gewissen Maße war die Kodierung der ursprünglichen Datenquellen fehlerhaft, was natürlich zu falschen Testergebnissen führt. Da diese Einträge nur einen kleinen Prozentsatz ausmachen und das Auffinden aller Einträge mit fehlerhafter Kodierung zeitraubend, wenn nicht unmöglich wäre, haben wir uns entschieden, dieses zusätzliche Problem zu akzeptieren und uns mit negativeren Ergebnissen abzufinden.
Doppelte ISBNs
Während unserer Tests haben wir festgestellt, dass einige ISBNs vielfach vergeben worden sind, was die Ergebnisse natürlich weiter verzerrt. Da diese Fälle selten sind, haben wir auch dieses Problem akzeptiert.
Ergebnis
Unsere ersten Tests haben in erster Linie eine Reihe von Problemen mit unserer Normalisierung zutage gefördert. Der erste Durchlauf mit der Standard-Bitlänge von 64 und einer Shingle-Size von 4 ergab 70,34% falsche Negative und 32,95% falsche Positive. Wir haben demgemäß die Normalisierung auf mehrere Arten verbessert:
Entfernung von Inhalt in Klammern
Viele Einträge enthielten Klammern innerhalb des Titels, in denen zum Beispiel eine Jahreszahl oder nähere Angaben zur Auflage enthalten waren.
Für die Normalisierung haben wir daher einen regulären Ausdruck hinzugefügt, um den von runden und eckigen Klammern eingeschlossenen Inhalt zu entfernen (das Entfernen der Klammern selbst war bereits Teil der Normalisierung). Diese neue Normalisierung hat die falschen Negative von 70,34% auf 66,92% verringert, die falschen Positive aber von 32,95% auf 35,79% erhöht.
Kürzen nach Doppelpunkt und Semikolon
In einigen Datensätzen folgte auf den Titel ein Doppelpunkt oder ein Semikolon und dann der Untertitel, ein zusätzlicher Hinweis oder gar eine Kurzbeschreibung des Buches. Wir haben die Normalisierung hinzugefügt, nach „:“ oder „;“ zu kürzen. Diese Normalisierung hat die falschen Negative von 66,92% auf 19,00% gesenkt. Wir haben damit die falschen Negative auf weniger als ein Drittel gesenkt.
Unsere Bedenken hinsichtlich einer steigenden Anzahl von falschen Positiven aufgrund einer solch drastischen Normalisierung haben sich als unbegründet herausgestellt; wir haben einen absoluten Anstieg der falschen Positive von 54% festgestellt; eine große Zahl von Einträgen, die das gleiche Werk referenzierten, bekamen nun die gleiche Meta-ID zugewiesen, weshalb die falschen Positive ebenfalls relativ von 35,79% auf 26,22% reduziert wurden.
| Echte Positive | Falsche Positive | Echte Negative | Falsche Negative | |
| Alte Normalisierung | 67,05% | 32,95% | 29,66% | 70,34% |
| Ohne Klammern | 64,21% | 35,79% | 33,08% | 66,92% |
| Kürzen nach : und ; | 73,78% | 29,22% | 81,00% | 19,00% |
Kürzen nach einer festgelegten Anzahl von Zeichen
Als Alternative zum Kürzen nach Doppelpunkt oder Semikolon könnte man nach einer gewissen Anzahl von Zeichen kürzen. Unseren Metadaten konnten wir entnehmen, dass das Titel-Feld durchschnittlich 41 Zeichen und das Autoren-Feld durchschnittlich 18 Zeichen enthielt. Wir haben uns vorgenommen, weitere Tests mit dieser Kürzungsmethode vorzunehmen.
Bitlänge und Shingle Size
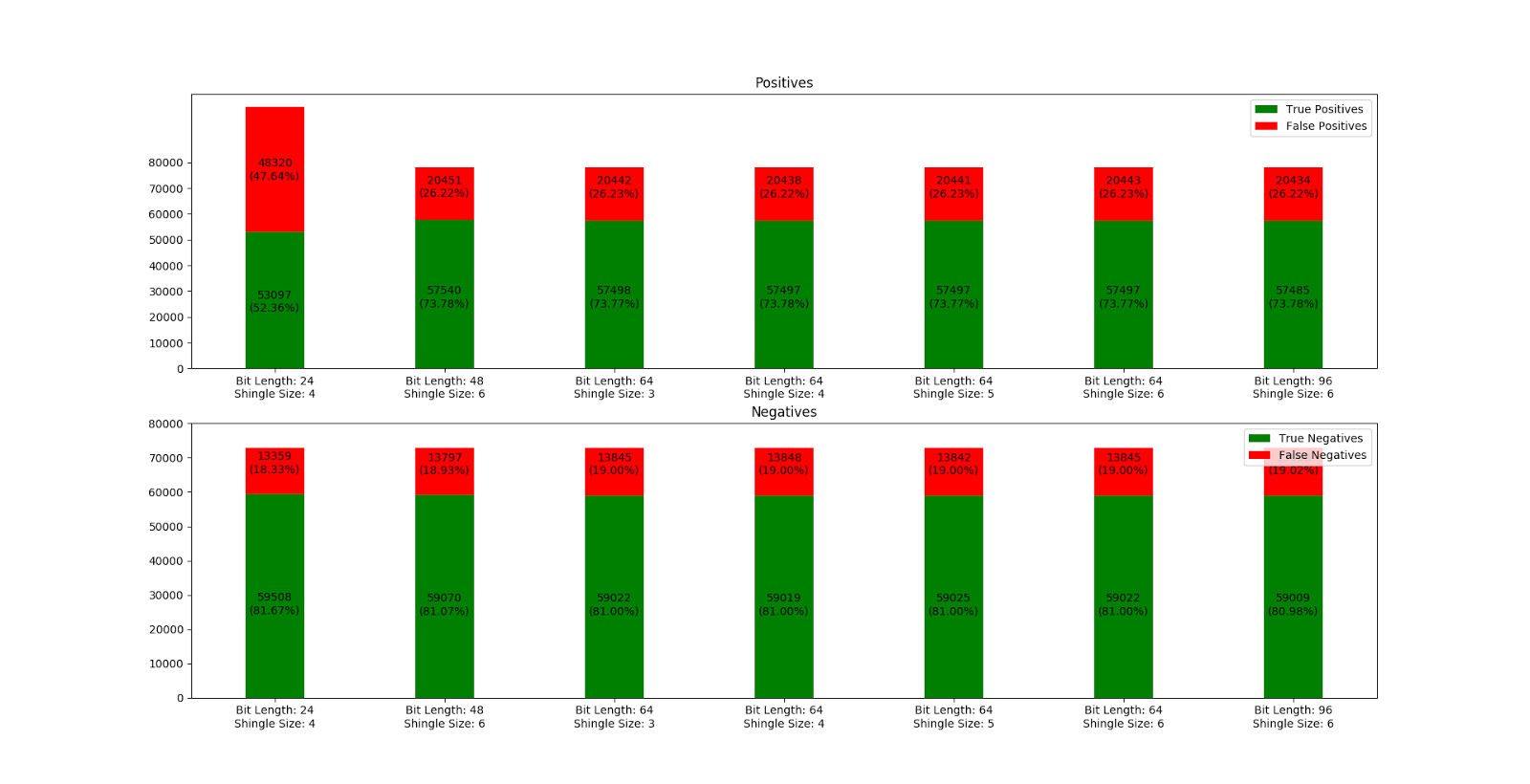
Im Anschluss an die Normalisierung haben wir unterschiedliche Kombinationen von Bitlänge und Shingle Size getestet. Interessanterweise zeigten diese Tests, dass diese Parameter bei den uns zur Verfügung stehenden Testdaten kaum einen Unterschied machen. Dennoch ergab der Test mit einer Bitlänge von 24 erwartungsgemäß bedeutend schlechtere Resultate, während wir jedoch andererseits in unserer ursprünglichen Planung von einer Bitlänge von 48, 64 oder 96 und einer Shingle-Size zwischen 3 und 6 ausgegangen sind.
Ausblick
Für den nächsten Milestone möchten wir die Normalisierung nach einer vorgegebenen Anzahl von Zeichen testen und sie mit dem Kürzen nach Doppelpunkt und Semikolon vergleichen. Eine weitere Möglichkeit ist das Kürzen nach Gedankenstrich, aber Gedankenstriche sind häufig ein normaler Bestandteil des Titels.
Zusätzlich möchten wir Testläufe für die Content-ID, Data-ID und Instance-ID durchführen, was ein schwierigeres Unterfangen sein wird, da es den Zugriff auf eine große Menge von Texten und Bildern bedingt.
