
ISCC Konzept
International Standard Content Code
von Titusz Pan
Das Internet wandelt sich zu einem Netzwerk dezentralisierter Peer-to-Peer-Transaktionen. Wenn wir wollen, dass unsere Transaktionen in den zukünftigen Blockchain-Netzwerken Content betreffen, brauchen wir standardisierte Methoden, Inhalte zu behandeln. Bei unseren Transaktionen kann es sich um Zahlungen handeln, um Zuordnungen, Renommee, Zertifizierung, Lizenzen oder gänzlich neuartige Formen der Übertragung von Werten. All dies wird viel schneller und einfacher geschehen, wenn wir als Community uns darauf einigen können, auf welche Weise Inhalte in einer dezentralisierten Umgebung identifiziert werden soll. Dies ist der erste Entwurf eines offenen, an die breitere Content-Community gerichteten Proposals für einen allgemeinen Content-Identifier. Wir möchten gerne unsere Ideen teilen und einen Austausch mit Journalisten, Nachrichtenagenturen, Kreativen, Verlagen, Distributoren, Büchereien, Musikern, Wissenschaftlern, Entwicklern, Juristen, Rechtevertretern und allen übrigen Teilnehmern des Content-Ökosystems initiieren.
Einleitung
Es gibt zahlreiche bestehende Standards für Medien-Identifier für eine breiten Palette an Einsatzzwecken. Im Verlagswesen wird beispielsweise die ISBN verwendet, Zeitschriften haben eine ISSN, die Musikindustrie nutzt ISRC, für Filme gibt es ISAN und die Wissenschaft hat DOI – jede einzelne davon dient einer Reihe spezifischer Zwecke. Diese Identifier spielen über viele Ebenen hinweg wichtige Rollen. Die Struktur und Verwaltung dieser globalen Identifier steht in engem Zusammenhang mit dem Grad der erreichbaren Automatisierung und dem Innovationspotential innerhalb verschiedener Sektoren der Medienindustrien und darüber hinaus. Einige Communitys wie der Online-Journalismus verfügen noch nicht einmal über irgendeinen dauerhaften, globalen Identifier für ihre Inhalte.
Viele der etablierten Standards wickeln die Registrierung von Identifiern in zentralisierten oder hierarchischen Systemen ab, die mit manuellen und kostenintensiven Abläufen verbunden sind. Häufig sind die dazugehörigen Metadaten für Dritte nicht auf einfache oder kostenfreie Weise zugänglich (wenn sie überhaupt zugänglich sind). Der Aufwand, die Kosten und die grundsätzlichen Eigenschaften dieser Systeme machen sie für viele innovative Anwendungszwecke ungeeignet. Bestehenden und etablierten Standards fällt es schwer, mit der sich rasant entwickelnden Digital Economy Schritt zu halten. So verlangen zum Beispiel die großen Ebook-Händler mittlerweile gar keine ISBN mehr und schaffen stattdessen ihre eigenen proprietären Identifier. Amazon nutzt die ASIN, Apple die Apple-ID und Google GKEY. Die rasante Entwicklung der digitalen Medienwirtschaft hat zu einer zunehmenden Fragmentierung von Identifiern und neuen Hürden hinsichtlich der Interoperabilität geführt. Für viele Aufgaben müssen die bestehenden Systeme all die verschiedenen firmenspezifischen IDs nachverfolgen und miteinander abgleichen – ein ineffizienter und fehleranfälliger Prozess.
Fortschritte bei Datenstrukturen, Algorithmen, maschinellem Lernen und der Aufstieg der Krypto-Ökonomien erlauben uns, neue Arten von Medien-Identifiern zu erfinden und vor dem Hintergrund innovativer Anwendungszwecke bestehende Identifier neu zu ersinnen. Blockchains und Smart Contracts bieten großartige Möglichkeiten hinsichtlich der Lösung zahlreicher Herausforderungen der Identifier-Registrierung wie zum Beispiel zentralisierte Verwaltung, Datenduplikation und -Vereindeutigung, Vendor lock-in und langfristige Datenspeicherung.
Dies ist ein offenes, an die Digital-Media-Community gerichtetes Proposal, das die Möglichkeiten eines dezentralisierten Content-Identifier Systems erkundet. Wir möchten einen offenen Standard für persistente, unikale, anbieterunabhängige und vom Inhalt abgeleitete, medienübergreifende Identifier etablieren, die in einer globalen und dezentralen Blockchain gespeichert und verwaltet werden. Uns schwebt ein selbstverwaltendes Ökosystem mit niedrigen Einstiegshürden vor, in dem kommerzielle und nichtkommerzielle Initiativen innovativ sein und nebeneinander gedeihen können.
Medien-Identifier für Blockchains
Medienkatalog-Systeme neigen dazu, auszuufern und komplex und häufig unbeherrschbar zu werden. Der von uns vorgeschlagene Entwurf konzentriert sich darauf, das ISCC-System so einfach und, wichtiger noch, so automatisierbar wie möglich zu halten, während gleichzeitig der praktische Nutzwert hinsichtlich der wichtigsten Anwendungszwecke maximiert wird ‒ das heißt, man soll mehr Nutzen daraus ziehen können, als man Arbeit hineinsteckt. Mit diesem Ziel vor Augen gelangen wir zu den folgenden grundlegenden Planungsentscheidungen:
Ein „bedeutungstragender“ Identifier
In traditionellen Datenbanksystemen wird empfohlen, mit Stellvertreterschlüsseln als Identifier zu arbeiten. Ein Stellvertreter- oder Surrogatschlüssel hat selbst keine Bedeutung und ist von den Daten, die er identifiziert, vollständig entkoppelt. Die Eindeutigkeit solcher Identifier wird entweder über zentralisierte, inkrementelle Zuweisung durch das Datenbanksystem garantiert oder über zufällige UUIDs, die eine sehr geringe Kollisionswahrscheinlichkeit aufweisen. Während zufällige UUIDs auf dezentralisierte Weise erzeugt werden könnten, benötigen doch beide Ansätze irgendeine zentrale Instanz, die die Verbindung zwischen dem Identifier und den zugehörigen Metadaten und dem Inhalt herstellt oder bescheinigt. Dies ist der Grund, warum wir uns entschieden haben, einen „bedeutungstragenden“ Content and Metadata Derived Identifier (CMDI) einzusetzen. Jeder wird in der Lage sein zu überprüfen, dass ein spezifischer Identifier in der Tat zu einem spezifischen Inhalt gehört. Besser noch, jeder kann den Identifier für einen bestimmten Inhalt „auffinden“, ohne dafür externe Datenquellen abfragen zu müssen. Dieser Ansatz erfasst außerdem wesentliche Informationen über das Medium direkt im Identifier, was hochgradig nützlich in Szenarien des maschinellen Lernens und der Datenanalytik ist.
Ein dezentralisierter Identifier
Wir möchten, dass unser Identifier unabhängig von Registrierungsinstanzen ist. Das bedeutet, dass Identifier in dezentralisierter und gleichzeitiger Weise auf dem Weg der Selbstvergabe ausgegeben werden können, ohne eine Genehmigung einzuholen. Selbst wenn Identifier nicht in einer zentralen Datenbank erfasst oder auf einer öffentlichen Blockchain gespeichert werden, sind sie noch immer in Fällen nützlich, in denen mehrere unabhängige Parteien Informationen über Inhalt austauschen. Der CMDI-Ansatz erweist sich bei verbreiteten Problemen wie Datenintegrität, Validierung, Deduplikation und Disambiguierung als hilfreich.
Speicher-Fragen
Bei einer typischen öffentlichen Blockchain werden alle Daten unter den Teilnehmern vollständig repliziert. Dies erlaubt eine unabhängige und autonome Validierung von Transaktionen. Sämtliche Blockchain-Daten sind hochverfügbar, manipulationssicher und kostenlos abrufbar. Unter hoher Last erzeugt die begrenzte Transaktions-Kapazität (Speicherplatz pro Zeiteinheit) jedoch einen Markt für Transaktionsgebühren. Dies führt zu wachsenden Transaktionskosten und macht Speicherplatz zu einer knappen und zunehmend wertvollen Ressource. Unser Identifier und das schlussendliche Metadaten-Schema müssen folglich zwingend sehr platzsparend sein, um maximalen Nutzen bei minimalen Kosten zu erreichen. Die grundlegenden Metadaten, die für das Erzeugen und Registrieren eines Identifiers notwendig sein werden, müssen sein:
von minimalem Umfang
klar spezifiziert
unanfällig für menschliches Fehlverhalten
auf technischer Ebene durchgesetzt
geeignet für öffentlichen Einsatz (keine rechtlichen oder Datenschutz-bezogenen Bedenken)
Ebenen der Identifikation digitaler Medien
Während der Untersuchung bestehender Identifier haben wir entdeckt, dass häufig einige Verwirrung herrscht hinsichtlich des Umfangs oder Erfassungsbereichs dessen, was von dem jeweiligen System tatsächlich identifiziert wird. Bei unserer Vorstellung von einem generischen, medienübergreifenden Identifier wollen wir besonderes Gewicht darauf legen, bei unseren Definitionen präzise zu sein, und fanden es hilfreich, zwischen „verschiedenen Ebenen der Identifikation digitaler Medien“ zu unterscheiden. Wir fanden, dass diese Ebenen auf einer Skala von abstrakt bis konkret auf natürliche Weise existieren. Unsere Analyse zeigte auch, das bestehende Standard-Identifier lediglich auf einer oder höchstens zwei solcher Ebenen arbeiten. Der ISCC wird als zusammengesetzter Identifier entworfen, der verschiedene Ebenen der Medien-Identifikation berücksichtigt:
Ebene 1 – abstraktes Werk
Auf der ersten und abstraktesten Ebene befassen wir uns mit der Unterscheidung verschiedener Werke oder Erzeugnisse im weitestmöglichen Sinne. Der Rahmen der Identifikation ist vollkommen unabhängig von jeglicher Manifestation des Werks, sei es digitaler oder physischer Natur. Er ignoriert außerdem Urheber, Rechteinhaber oder jegliche spezifischen Interpretationen, Ausdrucksformen oder Sprachversionen eines Werkes. Er nimmt lediglich Bezug auf die immaterielle Schöpfung – auf die Idee an sich.
Ebene 2 – semantisches Feld
Diese Ebene bezieht sich auf die Bedeutung oder das Wesentliche eines Werks. Er ist eine amorphe Sammlung oder Kombination von Fakten, Konzepten, Kategorien, Rubriken, Themen, Annahmen, Beobachtungen, Schlussfolgerungen, Vorstellungen und anderen immateriellen Dingen, die der Inhalt enthält. Der Rahmen der Identifikation besteht aus einer Reihe von Koordinaten innerhalb eines begrenzten und multidimensionalen semantischen Raums.
Ebene 3 – generische Manifestation
Auf dieser Ebene befassen wir uns mit der tatsächlichen Struktur einer spezifischen und normalisierten Manifestation eines Medientyps, namentlich dem grundlegenden Text-, Bild-, Audio- oder Video-Content, unabhängig von dessen semantischer Bedeutung oder Mediendatei-Kodierung und unter Duldung von Variationen. Diese „Duldung von Variationen“ fasst eine Reihe verschiedener Versionen mit Korrekturen, Überarbeitungen, Änderungen, Aktualisierungen, Personalisierungen, unterschiedliche Format-Kodierungen oder Datenkompressionen desselben Inhalts unter einem gruppierenden Identifier zusammen. Eine generische Manifestation ist unabhängig vom endgültigen digitalen Medienprodukt und bezieht sich spezifisch auf eine Ausdrucksform, Version oder Interpretation eines Werks.
Leider ist es nicht offensichtlich, wo eine generische Manifestation eines Werks endet und eine andere beginnt. Dies hängt von menschlicher Interpretation und dem Kontext ab. Wie viele Änderungen lassen wir zu, bevor wir von einer neuen „Manifestation“ sprechen und ihr einen unterschiedlichen Identifier zuweisen? Eine praktische, aber nur teilweise Lösung dieses Problems besteht darin, für jeden Medientyp ein algorithmisch definiertes und überprüfbares Spektrum der Duldung von Variationen zu schaffen. So lässt sich ein stabiler und wiederholbarer Ablauf bereitstellen, um zwischen generischen Content-Manifestationen zu unterscheiden. Es ist jedoch wichtig zu verstehen, dass man von einem solchen Prozess nicht erwarten darf, dass er Ergebnisse liefert, die stets für menschliche Erwartungen intuitiv sind hinsichtlich der Frage, wo genau die Grenzen gezogen werden sollten.
Ebene 4 – Medien-spezifische Manifestation
Diese Ebene bezieht sich auf eine Manifestation mit einer spezifischen Kodierung. Sie identifiziert ein Daten-File, das in einem spezifischen Medienformat kodiert und angeboten wird, wobei Abweichungen geduldet werden, um geringfügigen Veränderungen und Aktualisierungen innerhalb eines Formats Rechnung zu tragen, ohne einen neuen Identifier zu erzeugen. Man könnte zum Beispiel zwischen der PDF-, DOCX- oder WEBSITE-Version des gleichen Inhalts unterscheiden, wie sie anhand einer einzigen Quelle von einem Publishing-System generiert wird. Diese Ebene unterscheidet lediglich zwischen Produkten oder „Artefakten“ mit einer vorgegebenen Einbettung oder Kodierung.
Ebene 5 – exakte Repräsentation
Auf dieser Ebene identifizieren wir ein Daten-File anhand seiner exakten binären Erscheinungsform, ohne in irgendeiner Weise die Bedeutung zu interpretieren, sowie ohne Mehrdeutigkeit. Selbst eine minimale Änderung der Daten, die vielleicht keinen Einfluss auf die Interpretation des Inhalts hat, würde einen neuen Identifier erzeugen. Wie die ersten vier Ebenen sagt auch diese Ebene nichts über die örtliche Lage oder den Besitz des Inhalts aus.
Ebene 6 – individuelle Kopie
In der materiellen Welt würden wir ein bestimmtes Buch (eins das man aus seinem Bücherregal nehmen kann) eine individuelle Kopie nennen. Dies beinhaltet den Gedanken der örtlichen Lage und des Besitzes. In der digitalen Welt unterscheidet sich die Semantik einer individuellen Kopie deutlich. Eine individuelle Kopie könnte sich durch eine Lizenz, die man besitzt, auszeichnen, oder durch ein personalisiertes Wasserzeichen, das der Händler zum Zeitpunkt des Verkaufs anbringt, oder durch gewisse digitale Anmerkungen, die man seiner digitale Mediendatei hinzugefügt hat. Während es stets nur eine exakte Kopie eines materiellen Gegenstandes geben kann, können stets zahllose Reproduktionen einer „individuellen Kopie“ eines digitalen Gegenstandes existieren. Es ist sehr wichtig, diesen Unterschied nicht zu vergessen. Das Ignorieren dieser Tatsache hat zu zahllosen Missverständnissen geführt und hat in der gesamten Medienindustrie Verwirrung gestiftet – besonders im Bereich der Diskussionen um Copyright und Lizenzen.
Wir könnten versuchen, eine individuelle digitale Kopie anhand ihrer örtlichen Lage und dem exakten Inhalts auf einem spezifischen physischen Speichermedium (wie einer DVD, SSD …) zu definieren. Dies trägt jedoch dem Umstand nicht Rechnung, dass es nahezu unmöglich ist, jemanden davon abzuhalten, eine exakte Reproduktion jener Daten zu erstellen oder zumindest einen Schnappschuss oder eine Aufnahme von der Darstellung des Inhalts anzufertigen und an einem anderen Speicherort abzulegen.
Und der wichtigste Punkt: eine solche Reproduktion beeinflusst die ursprünglichen Daten nicht, und noch viel weniger kann sie dafür sorgen, dass das Original wie von Zauberhand verschwindet. Im Gegensatz dazu wird man, wenn man seine individuelle Kopie eines Buches einem anderen gibt, das Buch selbst nicht mehr „haben“. Es ist offensichtlich, daß dies bei digitalen Medien nicht verlässlich der Fall sein kann. Dies wäre nur auf dem Weg möglich, ein manipulationssicheres physisches Gerät zu bauen (ein sicheres Element), das die eigentlichen Daten nicht offenbart, was wiederum den Zweck verfehlen würde, da der Inhalt selbst dadurch unzugänglich bleibt. Es gibt jedoch Wege, auf denen sich solche von Natur aus physischen Eigenschaften teilweise in der digitalen Welt simulieren lassen. Vor allem mit dem Aufkommen der Blockchain-Technologie ist es nun möglich, ein kryptografisch gesichertes und öffentlich beglaubigtes, manipulationssicheres Besitz-Zertifikat zu bekommen. Dieses kann als Aufzeichnung einer Übereinkunft über den Besitz einer „individuellen Kopie“ dienen. Es setzt jedoch nicht aus sich selbst heraus die örtliche Lage oder Zugänglichkeit des Inhalts durch, noch beweist es die Autorität der zertifizierenden Partei oder die Rechtsgültigkeit der Übereinkunft.
Algorithmische Tools
Während viele Details der ISCC noch zur Diskussion stehen, sind wir uns hinsichtlich einiger grundsätzlicher Algorithmen, die Aufnahme in die endgültige Spezifikation des Identifiers finden werden, bereits recht sicher. Sie werden eine bedeutende Rolle bei der Art der Erzeugung der unterschiedlichen Bestandteile des Identifiers spielen:
Similarity preserving hash functions (Simhash, Minhash …)
Perceptual hashing (pHash, Blockhash, Chromaprint …)
Content defined chunking (Rabin-Karp, FastCDC …)
Merkle-Bäume
ISCC Proof-of-Concept
Bevor wir die Details des vorgeschlagenen ISCC-Identifiers endgültig festlegen, möchten wir eine einfache und reduzierte Proof-of-Concept-Implementierung unserer Ideen aufsetzen. Sie wird uns und anderen Entwickler ermöglichen, Tests mit realen Daten und Systemen vorzunehmen und bereits zu einem frühen Zeitpunkt herauszufinden, was funktioniert und was nicht.
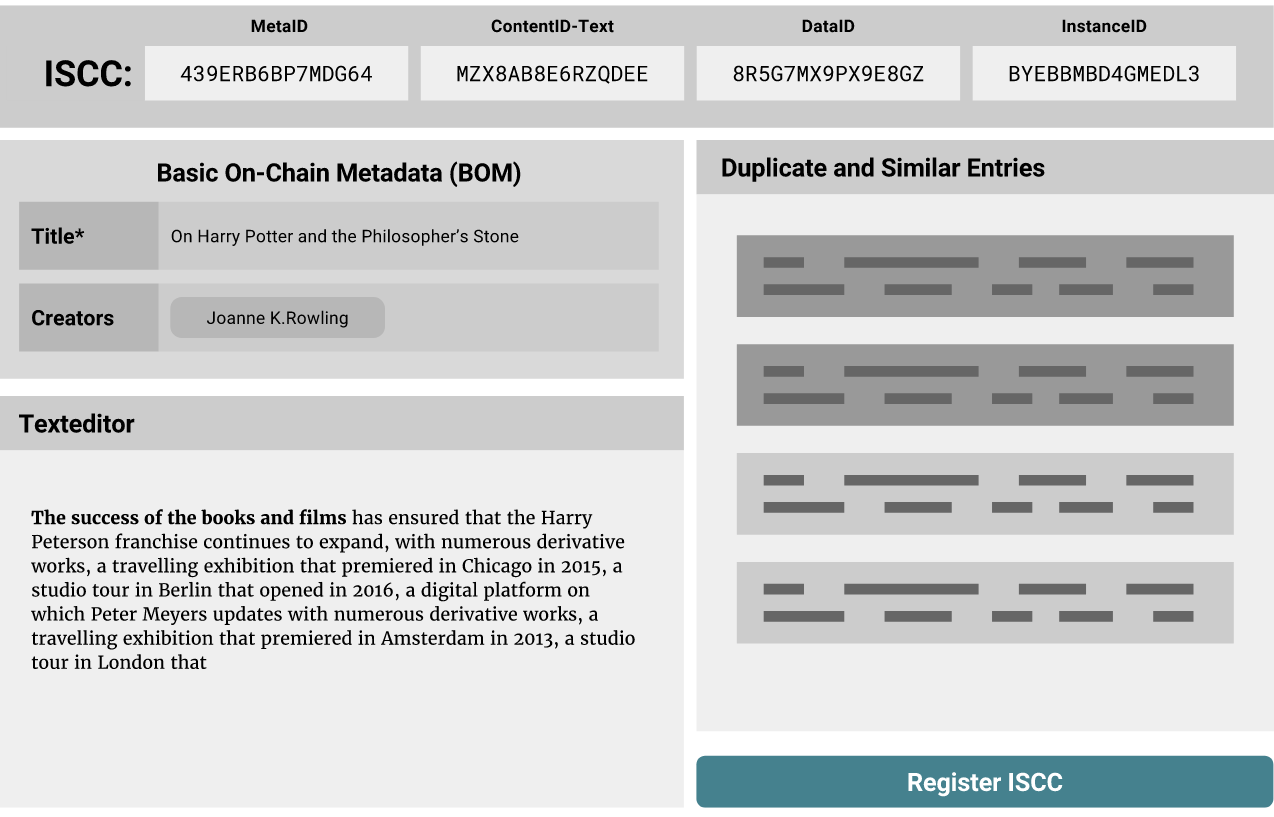
Die minimale praktikable, erste ISCC-Iteration wird eine Byte-Struktur sein, die sich aus den folgenden Komponenten zusammensetzt:
MetaID
Die MetaID wird als similarity-preserving hash aus minimalen Metadaten wie Titel und Urheber generiert. Sie operiert auf Ebene 1 und identifiziert eine materielle Schöpfung. Sie ist das erste und generischste Gruppierungselement des Identifiers. Wir werden mit verschiedenen N-Gram-Größen und Bit-Längen experimentieren, um die praktikablen Grenzen von Genauigkeit und Wiederabruf generischer Metadaten zu ermitteln. Wir werden außerdem einen Ablauf spezifizieren, mittels dessen unbeabsichtigte Kollisionen durch das Hinzufügen optionaler Metadaten vereindeutigt werden können.
Partial Content Flag
Das Partial Content Flag ist ein 1-Bit-Flag, das anzeigt, ob sich die verbleibenden Elemente auf das gesamte Werk beziehen oder nur auf eine Teilmenge desselben.
Media Type Flag
Das Media Type Flag ist ein 3-Bit-Flag, das uns erlaubt, zwischen bis zu acht verschiedenen generischen Medientypen (GMTs) zu unterscheiden, auf die unsere Content-ID-Komponente Anwendung findet. Wir definieren einen generischen Medientyp als basic content type wie Reintext oder Pixel-Rohdaten, der exakt spezifiziert werden wird und aus komplexeren Dateiformaten oder Kodierungen gewonnen wird. Wir werden mit generischen Text- und Bildformaten beginnen und später Audio, Video und Mischformate hinzufügen.
ContentID
Die ContentID operiert auf Ebene 3 und wird ein GMT-spezifischer similarity-preserving hash sein, der aus extrahiertem Inhalt generiert wird. Sie identifiziert den normalisierten Inhalt einer spezifischen GMT unabhängig vom Dateiformat oder der Kodierung. Sie nimmt Bezug auf die strukturelle Basis des Inhalts und gruppiert ähnliche GMT-spezifische Manifestationen der abstrakten Schöpfung oder Teilen derselben (die durch das Partial Content Flag ausgedrückt werden). Aus praktischen Gründen überspringen wir an diesem Punkt absichtlich Ebene-2-Komponenten. Sie würden eine grundlegende Proof-of-Concept-Implementierung unnötig komplex machen.
DataID
Die DataID operiert auf Ebene 4 und wird ein similarity-preserving hash sein, der aus shift-resistant content-defined chunks aus den Rohdaten des kodierten Medien-Blobs generiert wird. Sie gruppiert vollständig kodierte Dateien mit ähnlichem Inhalt und ähnlicher Kodierung. Diese Komponente unterscheidet nicht zwischen GMTs, da die Dateien mehrere unterschiedliche generische Medientypen enthalten können.
InstanceID
Die InstanceID operiert auf Ebene 5 und wird der oberste Hash-Wert eines Merkle-Baums sein, der aus (möglicherweise Content-definierten) Einheiten von Rohdaten eines kodierten Medien-Blobs erzeugt wird. Sie identifiziert eine konkrete Manifestation und belegt die Integrität des vollständigen Inhalts. Wir verwenden die Merkle-Baumstruktur, da sie uns erlaubt, die Integrität von Teileinheiten zu überprüfen, ohne die vollständigen Daten zur Verfügung zu haben. Dies wird sich in jeglichem Szenario der verteilten Datenspeicherung als nützlich erweisen.
Wir überspringen in diesem Stadium absichtlich Ebene 6, da örtliche Lage und Besitz von Inhalt auf dem Blockchain-Layer des Stacks verarbeitet werden wird, nicht vom ISCC-Identifier selbst.
Ein erster experimenteller Prototyp der ISCC-Idee ist auf Github in Entwicklung.
