
ISCC-Benchmarking
by Patricia Schinke
In this post, we give a quick summary of the tests that we ran up to now during the development of the ISCC. Each component of the ISCC shall have its proper round of test runs in order to ensure a smoothly working concept at the end of the development phase.
The first component of the ISCC is the Meta-ID. It is generated from the content’s metadata and shall serve to easily locate content. At the same time it shall help to group various editions and formats of digital content and avoid data duplication. To test our concepts regarding the ISCCs Meta-ID, we have gathered metadata and corresponding ISBNs from different open data sources and run tests on these data sets. Our goals with these test were:
- to determine the ideal bit length of the Meta-ID
- to determine the ideal shingle size for hashing
- to find further possible normalizations for the ISCC
Our tests with parsers for the different data sources are available at Github.
Our data sources
| Supplier | Number of entries | Format | Url |
| Open Library | 25 M | JSON | openlibrary.org/developers/dumps |
| DNB | 14 M | RDF | datendienst.dnb.de/cgi-bin/mabit.pl |
| Harvard | 12 M | MARC21 | library.harvard.edu/open-metadata |
| BX Books | 271,379 | CSV | www2.informatik.uni-freiburg.de/~cziegler/BX/ |
While parsing the data sources, only those records will be added that contain a title, at least one author and an ISBN. In cases of multiple authors, all authors will be added separated by “;“. ISBN-10 are converted into ISBN-13.
Title, authors, ISBN and the name of the data source are stored; records with identical metadata are only stored once.
Our tests
During parsing, we stored all eligible metadata in an Elasticsearch index.
After that, we generated the corresponding Meta-ID for each metadata entry from title and authors and stored it along with a link to the metadata entry in another index.
To test a variety of Meta-IDs, the Meta-ID index can be flushed at a later time to be refilled with Meta-IDs generated in a different way. This allows us to test different Meta-ID configurations without having to reparse the data sources for each test.
First test run
In the first test run, Meta-IDs were grouped by Meta-ID; in this process only those groups with entries coming from at least two different data sources were taken into consideration. The groups in which every Meta-ID is associated with the same ISBN was then counted, as well as the groups having at least two Meta-IDs for entries with different ISBNs. Two entries with identical Meta-ID should reference the same works, i.e. works with the same ISBN; thus we tried to maximize the first group, which we call “true negatives”, and minimize the second group, which we call “false negatives”.
Second test run
In the second test run, metadata was grouped by ISBN; similar to the first run, in this process only those groups with entries coming from at least two different data sources were taken into consideration. The groups in which the corresponding Meta-IDs are identical were then counted, as well as the groups having at least two different Meta-IDs. As with the first run, we wanted to maximize the first group, which we called “true positives”, and minimize the second group, which we call “false positives”, as two entries with the same ISBN represent the same work and should therefore get the same Meta-ID.
The test results are stored in another Elasticsearch index. Additionally, all ISBNs and Meta-IDs with collisions are stored in .txt files and are thus traceable in the Elasticsearch. Diagrams comparing the different test results can be created at any time.
Issues
During our tests we encountered several issues with regard to our results.
Slow parsing
The data formats of the sources are fairly old, and in some of them the authors are given merely as IDs. So we had to retrieve and link them from a separate data file. We tried to speed up the parsing wherever possible, e.g. by partially keeping the authors along with their IDs in the main memory. To further speed-up our tests we have stored the metadata in the Elasticsearch backend. This way we do not have to parse the data again for every test run.
Works may have multiple ISBNs
Works often receive a new ISBN for each new edition. Unfortunately, there is no book identifier that uniquely references a work across several editions. This is one of the problems we seek to solve with the ISCC, but it’s difficult to determine to what extent the Meta-ID is up to this task. Lacking alternatives, we nonetheless used the ISBN as identifier and accepted, that the results turn out more negatively.
Broken encoding
To some extent, the encoding of the data sources themselves was corrupt, which of course leads to incorrect test results. As these entries make up only a small percentage and finding all entries with broken encoding would be time-consuming, if not impossible, we decided to accept this further issue and put up with more negative results.
Duplicate ISBNs
During our tests we found that some ISBNs have been assigned manyfold, which of course further distorts the results. As these cases are rare, we accepted this issue, too.
Results
Our initial tests have revealed primarily a number of issues with our normalization. Our first run with our standard bit length of 64 and a shingle size of 4 produced 70.34% false negatives and 32.95% false positives. We have thus improved the normalization in several ways:
Removal of content in brackets
Many entries had brackets within the title containing for example a year or some explanatory note regarding the edition.
For normalization purposes we thus added a regular expression to delete the content inside round “(“ and square “[“ brackets (the removal of the brackets themselves was already part of the normalization process). This new normalization reduced our false negatives from 70.34% to 66.92%, but increased the false positives from 32.95% to 35.79%.
Truncating after colon and semicolon
In some data records, the title was followed by a colon or semicolon and the subtitle, an explanatory note or even a short description of the book. We added the normalization of truncating after “:” or “;”. This normalization reduced the false negatives from 66,92% to 19.00%. We have thus reduced false negatives to less than a third.
Our fears of a rising number of false positives due to such a drastic normalization has proven false; we saw an absolute rise in false positives of 54%, however, a large number of entries referencing the same works were now assigned the same Meta-ID, which is why the false positives were also reduced relatively from 35.79% to 26.22%.
| True positives | False positives | True negatives | False negatives | |
| Old normalization | 67.05% | 32.95% | 29.66% | 70.34% |
| Without brackets | 64.21% | 35.79% | 33.08% | 66.92% |
| Truncating after : and ; | 73.78% | 29.22% | 81.00% | 19.00% |
Truncating after a given number of characters
As an alternative to truncating after a colon or semicolon, we could truncate after a certain number of characters. We saw from our metadata that the title field contains an average of 41 characters and the creators field an average of 18 characters. We are planing to do further tests with this method of truncating.
Bit length and shingle size
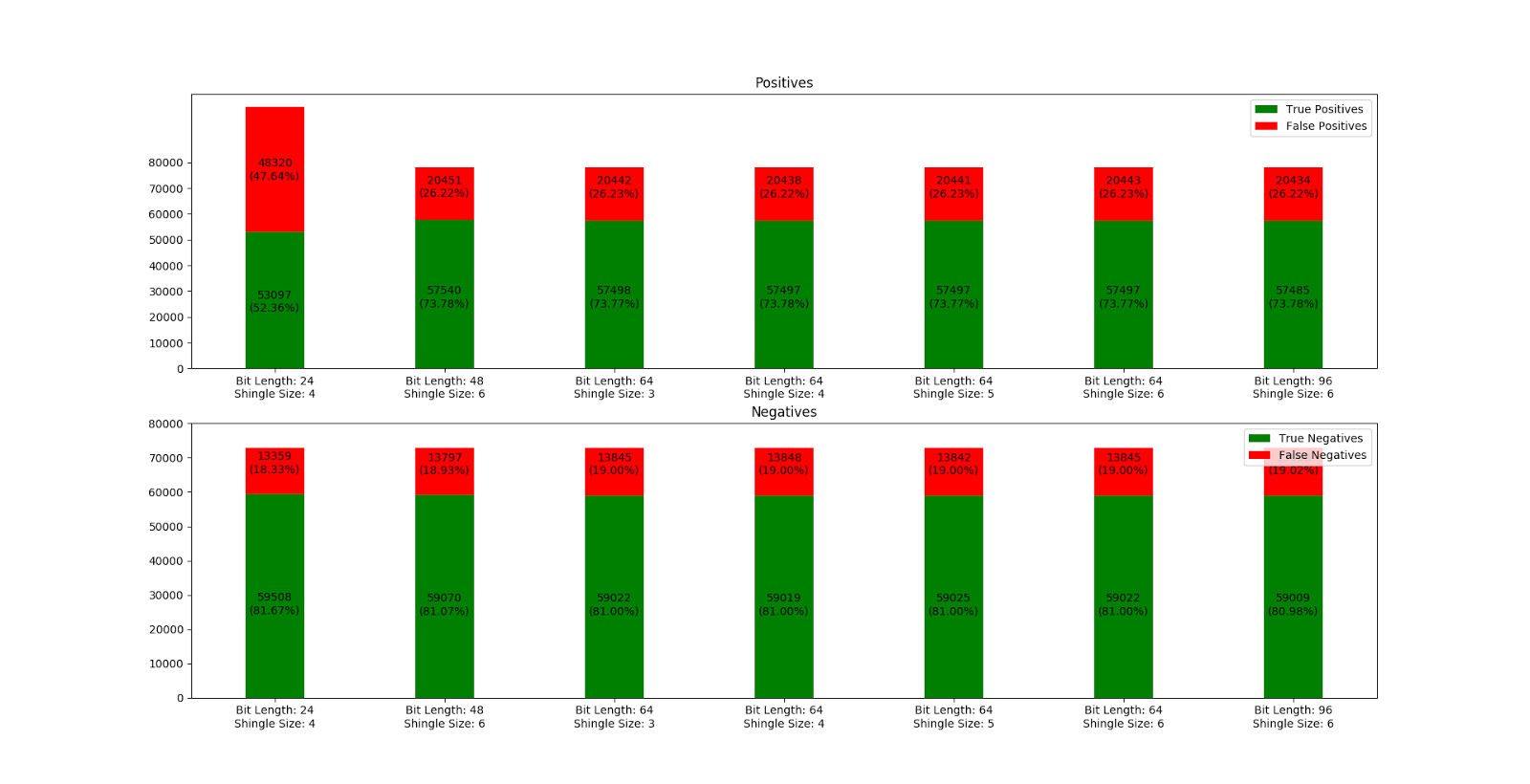
Subsequent to the normalization process we tested various combinations of bit length and shingle size. Interestingly, the tests showed that with the amount of test data available to us, these parameters make hardly any difference. Still, as one would expect, our test with a bit length of 24 produced considerably worse results, but then again we initially planned with a bit length of 48, 64 or 96 and a shingle size between 3 and 6.
Outlook
For the next milestone we want to test normalization after a given number of characters and compare it to truncating after colon and semicolon. Another option is to truncate after a dash, but dashes are frequently a normal part of the title.
In addition, we want to run tests for the Content-ID, Data-ID and Instance-ID, which will be a more difficult task, as it requires a large stock of texts and images.
