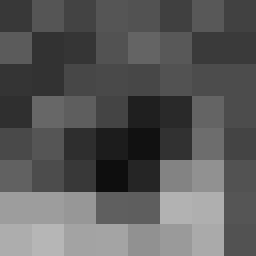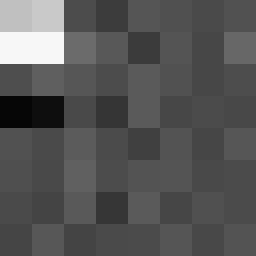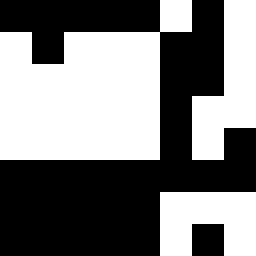


The perceptual hash algorithm, too, initially calculates the gray value image and scales it down. In our case, we desire a factor of 4, which is why we scaled down to 8*4×8*4, that is, a 32×32 image.
To this image we apply a discrete cosine transform, first per row and afterwards per column.
Discrete cosine transform: ![]()
The pixels with high frequencies are now located in the upper left corner, which is why we crop the image to the upper left 8×8 pixels. Next, we calculate the median of the gray values in this image and generate, analogous to the median hash algorithm, a hash value from the image.